
google got all fat & rich because of one single reason: they excel at sorting search engine hits. the secret behind this is called PageRank, a clever algorithm to sort links. they even explain the basics of how that works on their homepage. how nice of them.
but hold on a second. if all of their success was based on one single business secret, why in the world would they be talking so openly about it on their webpage? granted, they don’t give any implementation details there, but still, why put the competitors/cloners on the right track with information about the way PageRank works?
personally, i think it’s a priori much more likely that the information about PageRank on the google homepage is deliberately misleading, so as to fool the competition (and the general public…).
but what else could be google’s secret, then?
well, try this: go to google and search for ‘antoine meillet’ (feel free to use your favourite linguist instead ;). look at the results and hover over the links. you will see nothing strange: the full URL in the status bar will indicate that they are direct links to the target webpage.

or maybe not? check out the source code of the google result page (on firefox, select the text and choose ‘view selection source’ from the right-click menu – god i love that browser). surprise, surprise: the href attribute does in fact not show a direct link to the target (we expect: href=”http://en.wikipedia.org/wiki/Antoine_Meillet”), but instead shows something really cryptic like:
href=”/url?sa=t&source=web&ct=res&cd=1&url=http%3A%2F%2Fde.wikipedia.org%2Fwiki%2FAntoine_Meillet&ei=IzJQSaP3JY_m0gXV7KWEBA&usg=AFQjCNFHbV4saUM80cY7BQ6pfEYNAGnD0A&sig2=a9sZLl2cPM-V7WC5dGs–A”
now what exactly that means (and how they manage to still show the simple address in the browser’s status page) is a mystery to me. but what seems quite obvious is that people are in fact never directly forwarded to the target site when they click on the google search hit. instead, it looks like they are secretly routed back through google HQ. now since it’s rather difficult to figure out what exactly happens if you click on that link (too much javascript involved…), it’s easier to just log the browser’s activity to see what’s going on behind the scenes. sounds like a job for wireshark.
here’s wireshark’s list of the all HTTP/GET requests that happend on my network interface when clicking on one of the links from google’s search result:
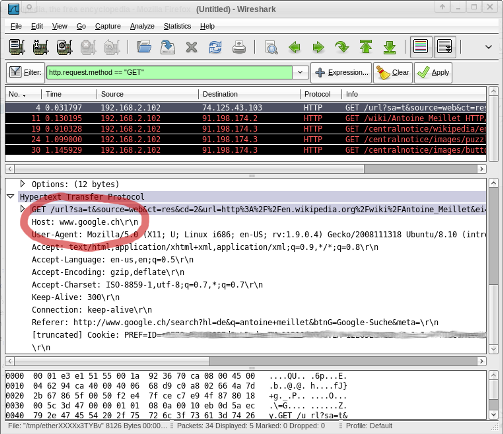
notice that the first HTTP/GET request went back to google! only the second (and the following ones) went to wikipedia:

with the help of wireshark, we have therefore confirmed that the users are being routed back through google before they reach their actual destination, so the question is: what could be the purpose of this? simple: google will store the key words of your search along with those hits from the search result that you actually clicked on, trusting that you will look through the list of results that google presents and choose the relevant hit(s) from among them. with this information, they will increase the ranking of the hits you clicked on, and decrease the ranking of those hits which you skipped, all in relation to your specific search keywords.
if true, it means that google does in fact let the users do the sorting for them. humans are much better at sorting out relevant hits from among a mass of unrelevant ones, and since google has the possibility to collect that information, why not use it to improve the ranking? it seems not too far fetched, then, to suspect that the core of PageRank is in fact not a fancy algorithm at all – but that it is simply a clever way to let the users rank the search results for them, by (secretly) collection data on which hits the users clicked on and which ones they didn’t.
ps: further investigation showed that the cryptic links in the source of google’s search result pages are not always there. but even in those cases, wireshark shows a HTTP/GET request sent to google before the loading of the actual link target.
